After months of writing, editing, and procrastinating, my new ebook, “Practice Makes Regexp” is almost ready. The book (similar to my earlier ebook, “Practice Makes Python“) contains 50 exercises to improve your fluency with regular expressions (“regexps”), with solutions in Python, Ruby, JavaScript, and PostgreSQL.
When I tell people this, they often say, “PostgreSQL? Really?!?” Many are surprised to hear that PostgreSQL supports regexps at all. Others, once they take a look, are surprised by how powerful the engine is. And even more are surprised by the variety of ways in which they can use regexps from within PostgreSQL.
I’m thus presenting an excerpt from the book, providing an overview of PostgreSQL’s regexp operators and functions. I’ve used these many times over the years, and it’s quite possible that you’ll also find them to be of assistance when writing queries.
PostgreSQL
PostgreSQL isn’t a language per se, but rather a relational database system. That said, PostgreSQL includes a powerful regexp engine. It can be used to test which rows match certain criteria, but it can also be used to retrieve selected text from columns inside of a table. Regexps in PostgreSQL are a hidden gem, one which many people don’t even know exists, but which can be extremely useful.
Defining regexps
Regexps in PostgreSQL are defined using strings. Thus, you will create a string (using single quotes only; you should never use double quotes in PostgreSQL), and then match that to another string. If there is a match, PostgreSQL returns “true.”
PostgreSQL’s regexp syntax is similar to that of Python and Ruby, in that you use backslashes to neutralize metacharacters. Thus, + is a metacharacter in PostgreSQL, whereas \+ is a plain “plus” character. However, there are differences between the regexp syntax —for example, PostgreSQL’s word-boundary metacharacter is \y whereas in Python and Ruby, it is \b. (This was likely done to avoid conflicts with the ASCII backspace character.)
Where things are truly different in PostgreSQL’s implementation is the set of operators and functions used to work with regexps. PostgreSQL’s operators are generally aimed at finding whether a particular regexp matches text, in order to include or exclude result rows from an SQL query. By contrast, the regexp functions are meant to retrieve some or all of a string from a column’s text value.
True/false operators
PostgreSQL comes with four regexp operators. In each case, the text string to be matched should be on the left, and the regexp should be on the right. All of these operators return true or false:
- ~ case-sensitive match
- ~* case-insensitive match
- !~ case-sensitive non-match
- !~* case-insensitive non-match
Thus, you can say:
select 'abc' ~ 'a.c'; -- returns "true"
select 'abc' ~ 'A.C'; -- returns "false"
select 'abc' ~* 'A.C'; -- returns "true"
In addition to the standard character classes, we can also use POSIX-style character classes:
select 'abc' ~* '^[[:xdigit:]]$'; -- returns "false"
select 'abc' ~* '^[[:xdigit:]]+$'; -- returns "true"
select 'abcq' ~* '^[[:xdigit:]]+$'; -- returns "false"
This operator, as mentioned above, is often used to include or exclude rows in a query’s WHERE clause:
CREATE TABLE Stuff (id SERIAL, thing TEXT);
INSERT INTO Stuff (thing) VALUES ('ABC'), ('abc'), ('AbC'), ('Abq'), ('ABCq');
SELECT id, thing FROM Stuff WHERE thing ~* '^[abc]{3}$';
This final query should return three rows, those in which thing is equal to abc, Abc, and ABC.
Extracting text
If you’re interested in the text that was actually matched, then you’ll need to use one of the built-in regexp functions that PostgreSQL provides. For example, the regexp_match function allows us not only to determine whether a regexp matches some text, but also to get the text that was matched. For each matching column, regexp_match returns an array of text (even if that array contains a single element). For example:
CREATE TABLE Stuff (id SERIAL, thing TEXT);
INSERT INTO Stuff (thing) VALUES ('ABC'), ('abc'), ('AbC'), ('Abq'), ('ABCq');
SELECT regexp_matches(thing, '^[abc]{3}$') FROM Stuff;
The above will return a single row:
{abc}
As you can see, the above returned only a single column (from the function) and a single row (i.e., the one matching it). That’s because when you invoke regexp_matches, you can provide additional flags that modify the way in which it operates. These flags are similar to those used in Python, Ruby, and JavaScript.
For example, we can use the i flag to make regexp_match case-insensitive:
CREATE TABLE Stuff (id SERIAL, thing TEXT);
INSERT INTO Stuff (thing) VALUES ('ABC'), ('abc'), ('AbC'), ('Abq'), ('ABCq');
SELECT regexp_matches(thing, '^[abc]{3}$', 'i') FROM Stuff;
Now we’ll get three rows back, since we have made the match case-insensitive. regexp_matches can take several other flags as well, including g (for a global search). For example:
CREATE TABLE Stuff (id SERIAL, thing TEXT);
INSERT INTO Stuff (thing) VALUES ('ABC');
SELECT regexp_matches(thing, '.', 'g') FROM Stuff;
Here is the output from regexp_matches:
{A}
{B}
{C}
Notice how regexp_matches, because of the g option, returned three rows, with each row containing a single (one-character) array. This indicates that there were three matches.
Why is each returned row an array, rather than a string? Because if we use groups to capture parts of the text, the array will contain the groups:
CREATE TABLE Stuff (id SERIAL, thing TEXT);
INSERT INTO Stuff (thing) VALUES ('ABC'), ('AqC');
SELECT regexp_matches(thing, '^(A)(..)$', 'ig') FROM Stuff;
Notice that in the above example, I combined the i and g flags, passing them in a single string. The result is a set of arrays:
| regexp_matches |
|----------------|
| {A,BC} |
| {A,qC} |
Splitting
A common function in many high-level languages is split, which takes a string and returns an array of items. PostgreSQL offers this with its split_part function, but that only works on strings.
However, PostgreSQL also offers two other functions: regexp_split_to_array and regexp_split_to_table. This allows us to split a text string using a regexp, rather than a fixed string. For example, if we say:
select regexp_split_to_array('abc def ghi jkl', '\s+');
The above will take any length of whitespace, and will use that to split the columns. But you can use any regexp you want to split things, getting an array back.
A similar function is regexp_split_to_table, which returns not a single row containing an array, but rather one row for each element. Repeating the above example:
select regexp_split_to_table('abc def ghi jkl', '\s+');
The above would return a table of four rows, with each split text string in its own row.
Substituting text
The regexp_replace function allows us to create a new text string based on an old one. For example:
SELECT regexp_replace('The quick brown fox jumped over the lazy dog',
'[aeiou]', '_');
The above returns:
Th_ quick brown fox jumped over the lazy dog
Why was only the first vowel replaced? Because we didn’t invoke regexp_replace with the g option, making it global:
SELECT regexp_replace('The quick brown fox jumped over the lazy dog',
'[aeiou]', '_', 'g');
Now all occurrences are replaced:
Th_ q__ck br_wn f_x j_mp_d _v_r th_ l_zy d_g
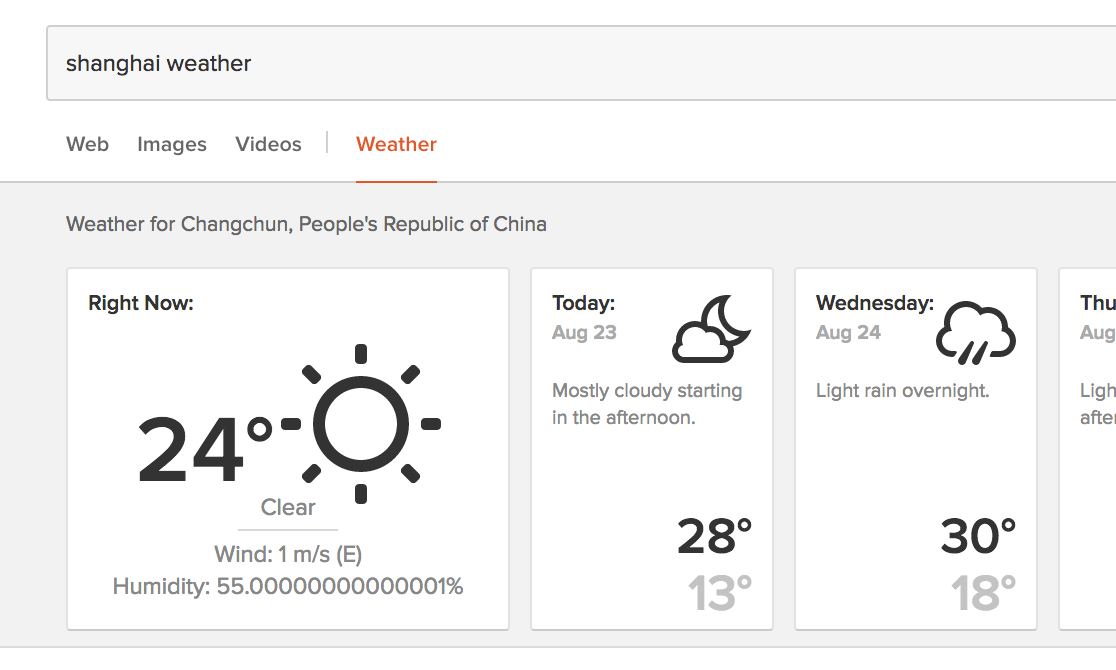 Never mind that it gave me a weather report for the wrong Chinese city. Take a look at the humidity reading! What’s going on there? Am I supposed to worry that it’s ever-so-slightly more humid than 55%?
Never mind that it gave me a weather report for the wrong Chinese city. Take a look at the humidity reading! What’s going on there? Am I supposed to worry that it’s ever-so-slightly more humid than 55%?
 And so, I’m delighted to announce the launch of my second ebook, “
And so, I’m delighted to announce the launch of my second ebook, “