If you want to improve your understanding of Python, then you’re going to have to practice.
And as hundreds of developers from around the world have already learned, there’s no better way to practice than Weekly Python Exercise.
If you’re relatively new to Python, this our upcoming cohort is for you! Weekly Python Exercise: Newbie Edition, will be starting soon. Enjoy 15 weeks of beginner-level exercises (and solutions), along with a private forum for collaboration, and regular office hours with me.
Click to learn more, including seeing a free sample of WPE and how it works.
I’m excited about this new cohort — and if you want to get better at Python, then I hope you’ll join me!
Python is one of the hottest languages out there. People can’t get enough Python, and companies can’t get enough Python people.
This means that learning Python is a great move for your career. (Also, it’s just plain ol’ fun to use.)
If you’ve always wanted to get started with Python, or if you’ve been using it by combining good guesses with many visits to Stack Overflow, then I’m happy to announce the release of my new course, “Intro Python: Fundamentals.”
This course is meant for experienced programmers with up to six months of Python experience. It covers the language’s basic syntax, and the core data structures: Numbers, strings, lists, tuples, dicts, and sets. And of course, it uses the current (3.7) version of Python.
The course has nearly 7 hours of video (in 79 lectures), plus 11 exercises to practice and improve your Python fluency. It’s the same material I cover on the first day of the four-day intro Python class that I give to companies around the world.
You can read more about the course here. As with all of my courses, I offer discounts to students, retirees/pensioners, and people living outside of the world’s 30 richest countries — just contact me at reuven@lerner.co.il for the appropriate discount code.
So if you’ve ever wanted to learn Python, or just want to strengthen your understanding of how Python’s core data structures work, take a look at “Intro Python: Fundamentals“.
[Construction notice: I’m rewriting this article to reflect the (bad) situation for foreigners using WeChat, and the (amazingly good) situation for foreigners using AliPay. I hope that the rewrite will be done by soon, but covid-19 has made my schedule even more unpredictable than before. My apologies for the verbal dust that’ll be around until then.]
Since 2014, I have traveled to China several times each year on business (to teach my courses in Python and data science at high-tech companies). On my first few trips, I tried to use my credit card to pay for things — as I’m used to doing in Israel, the US, and Europe. But I quickly discovered that most businesses don’t take credit cards, and they certainly don’t take foreign credit cards. Everything, but everything, was done in cash.
And thus, on those first few trips, I smugly thought to myself: I wonder when China will finally advance enough to use credit cards?
And so, after years of walking around with almost no cash on me, my trips to China would inevitably involve going to ATMs every 2-3 days, taking out large wads of cash, and using them for just about everything — groceries, restaurants, and taxis. I was warned to always check my 100 RMB bills, to see if they’re fake, because counterfeiting was rampant. And indeed, whenever I would pay with such a bill, the recipient would inspect it to make sure that I wasn’t giving them a fake.
Fast forward several years, and I can confidently say that China won’t ever “advance” to use credit cards. That’s because they have gone beyond credit cards to use their phones. People use AliPay (run by Alibaba, the parent of e-commerce giant Ali Express and Tao Bao) or WeChat pay (run by Tencent, owners of the ubiquitous chat and application platform).
For at least two years, I tried and failed to get phone-based payments to work. This became increasingly problematic; not only was I still going to ATMs on a regular basis, but I was getting funny looks from taxi drivers and waitresses, all of whom were disappointed that another primitive foreigner was forcing them to use cash. But for the longest time, I couldn’t pay with my phone to work.
Finally, in August 2018, I was able to get WeChat payments to work. This marked a sea change in my ability to get around in China. Not only was it easy and fun, but it impressed the locals. And I didn’t have to visit an ATM even once. I continue to visit China every 3-5 months for work, and I can say that with great confidence that phone-based payments are convenient and great.
I went through a lot of pain on my way to getting phone-based payments to work. I’m sharing my experiences here so that others can learn from them, and enjoy using phone-based payments when they’re in China. Indeed, the original version of this article indicated that WeChat was available to foreigners and AliPay isn’t; this is no longer the case, and I’m updating the article to reflect that.
What are phone-based payments?
The first question you might be asking is, “What does it mean to pay on my phone?” The basic idea is that you transfer money from a bank account (more on this in a bit) onto your phone. You can then transfer money from the account on your phone to the account on someone else’s phone.
That is: You’ll effectively be opening a new bank account with WeChat. If you have 1,000 RMB in your WeChat account, then you can transfer up to 1,000 RMB to someone else with WeChat. The moment you do that, the money disappears from your account, and appears in theirs — your phone will show that you have less, and your friend’s phone will show that they have more. The transfer is instantaneous and free.
For example, let’s say that you go out to dinner with friends. Your friend pays 100 RMB for dinner, and you want to split the cost. If you both use WeChat, then you can send 50 RMB from your WeChat account to your friend’s WeChat account. Within moments, your WeChat account has 50 RMB less, and your friend’s account has 50 RMB more.
To many Westerners, this sounds just like PayPal. And it is, except that it’s far easier and faster to use. And it is completely free. That’s right — if you send 50 RMB, then your friend gets 100% of it, without any fees for either of you.
Moreover, no bank account is actually involved: You’re moving money from one WeChat account to another. Until and unless you move the money from your WeChat account to your bank account (which, as a foreigner, you won’t be able to do), the people who actually have your money is WeChat.
Still, this doesn’t sound that different from using a credit card, or doing an electronic transfer from one bank account to another. Except that it is. The user experience is completely different. And the fact that everyone — absolutely everyone! — uses phone-based payments in China has turned it into a seamless part of commerce, and ridiculously easy to use.
So, what’s the problem?
If you have a Chinese phone number and bank account, then there is no problem. You transfer money from your Chinese bank account to your WeChat or AliPay account, and you’re good to go. This guide isn’t for you.
If you don’t have a Chinese phone number and bank account, then the WeChat doesn’t officially know what to do with you. So far as I can tell, you’re officially not even allowed to use it.
Indeed: For several years, I tried to use WeChat for payments, but the “wallet” feature wasn’t even available on my version of WeChat. Chinese friends and colleagues were skeptical that I didn’t have this functionality, but when they saw that the menu option didn’t exist on my copy of WeChat, they didn’t quite know what to say.
This guide is meant to help you, the foreigner traveling to China without a Chinese phone number or bank account, to use phone payments. I can’t guarantee that this will work — but it did work for me, and has for several other people I know.
If this guide is helpful, then let me know! And if it doesn’t work, then let me know where you get stuck, and I’ll see what I can do to help. You can always reach me as “ReuvenLerner” on WeChat, reuven@lerner.co.il via e-mail, or @reuvenmlerner on Twitter.
The software
If you want to use WeChat payments, you’ll need to install.. WeChat. That’s right, nothing more than that. However, if you’re planning to visit China, then you should realize that your access to the App Store (iPhone) or Google Play (Android) will be cut off while there. Thus, it’s crucial that you install WeChat before you visit China.
(I would also recommend installing a VPN (virtual private network) on your phone before you go to China, so that you can use your favorite non-Chinese apps. Don’t have a VPN? I’ve used ExpressVPN for several years, and am delighted with how it works, both in China and in other countries. Visiting China without ExpressVPN, or another VPN service, is a really bad idea — because once you get there, you won’t be able to download or install it easily.)
You can set WeChat to work in either Chinese or English. My Chinese is getting better, but I still stick with using it in English, and my instructions here will assume that you’re doing that, too.
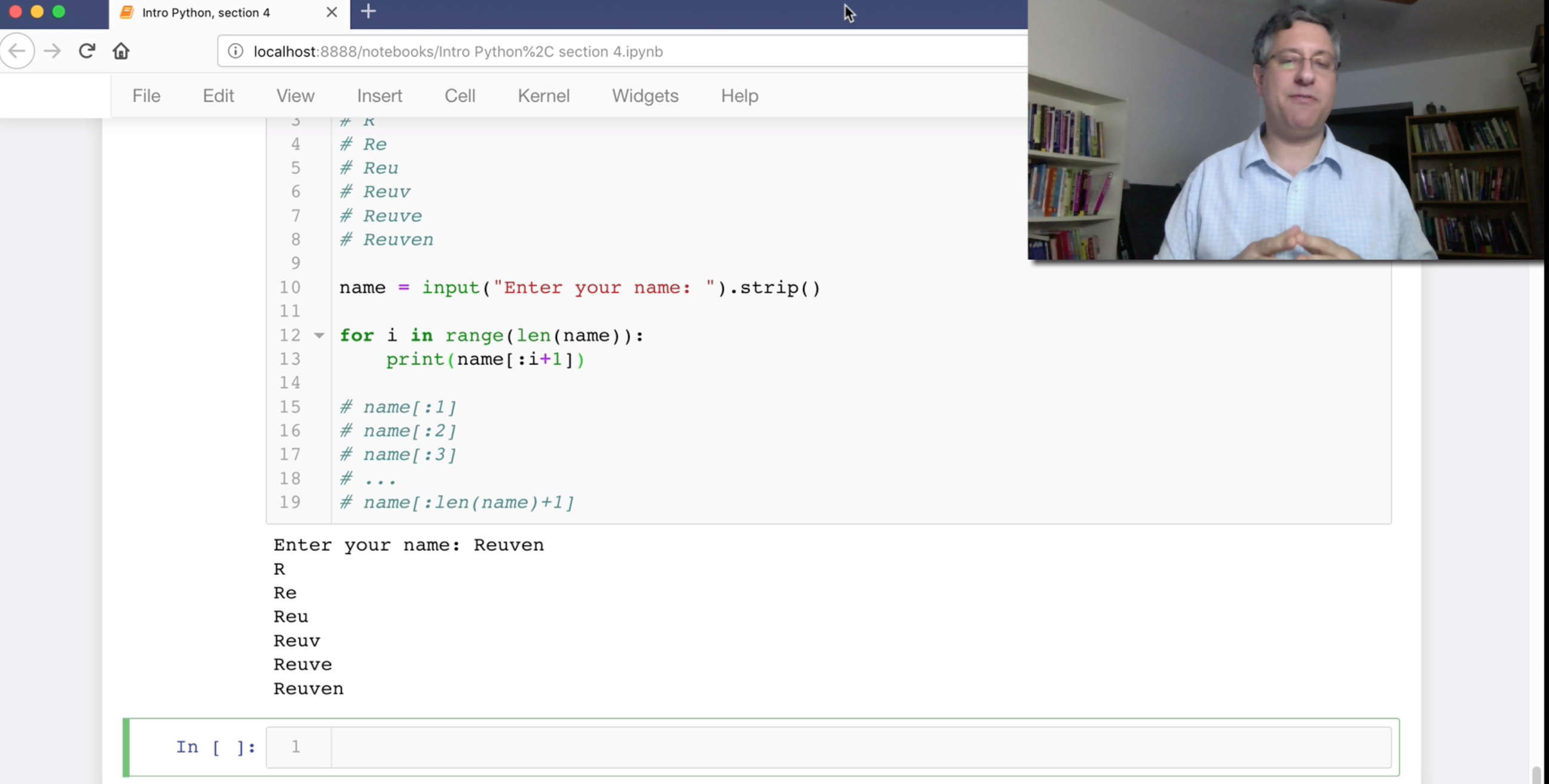
Installing WeChat generally means downloading and installing the software, and choosing a username. I chose what I thought was a normal username, based on my first and last names (“ReuvenLerner”) — but it seems that many people in China simply use their phone number as their username. This doesn’t really matter very much, because almost no one in China ever enters a username; rather, you scan the other person’s phone to add them. That is: Sure, you can add me as “ReuvenLerner” on WeChat by typing my username. But why would you do that, when you can scan a QR code?
Indeed, QR codes are a primary way in which WeChat users communicate and share information (and payments, as we’ll soon see).
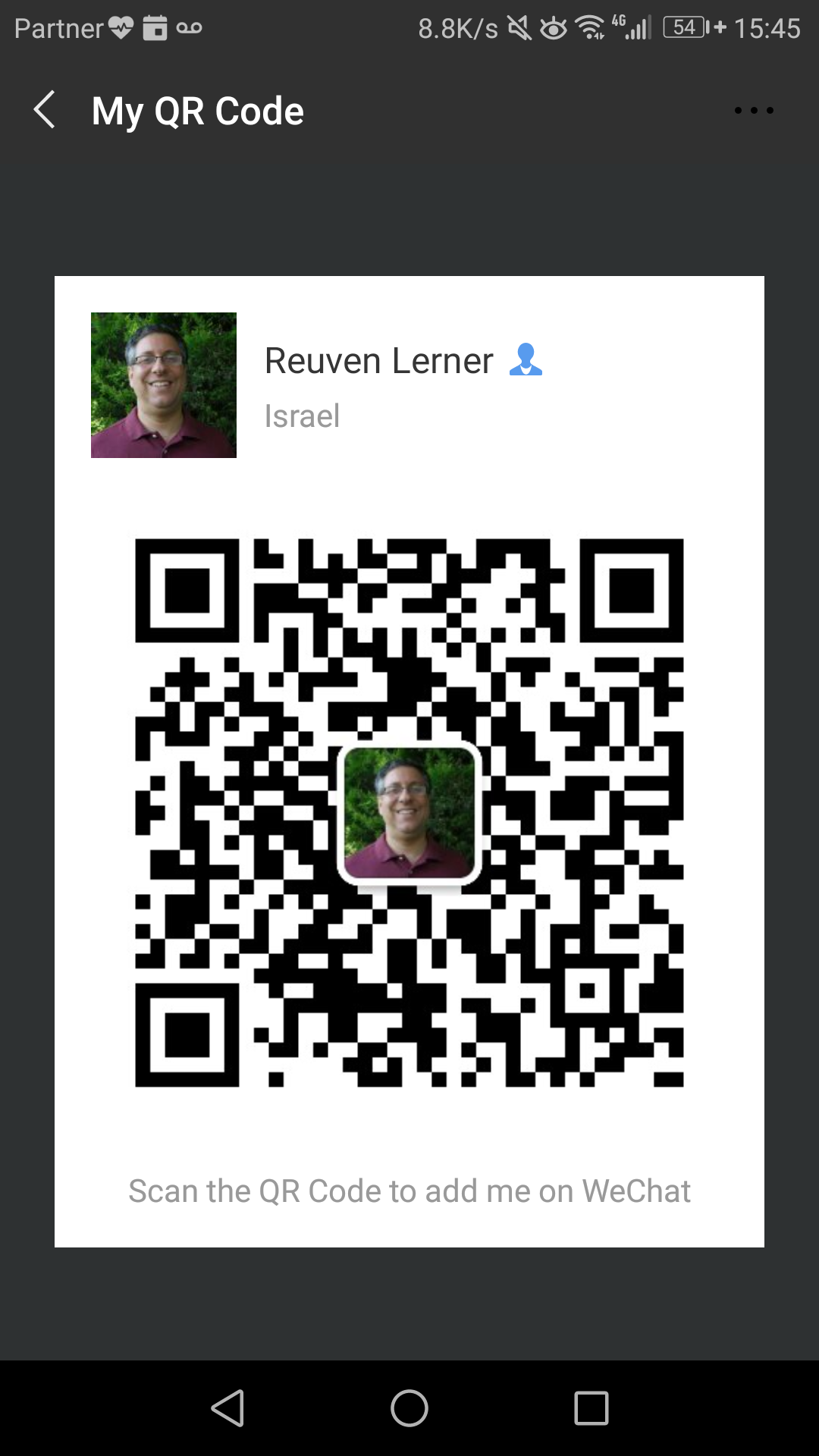
If I want you to add me, then I can go into WeChat and press the “me” button in the lower right. At the top, next to your picture, there’s a small bar code. Press on that, and you’ll get a QR code that other people can scan.
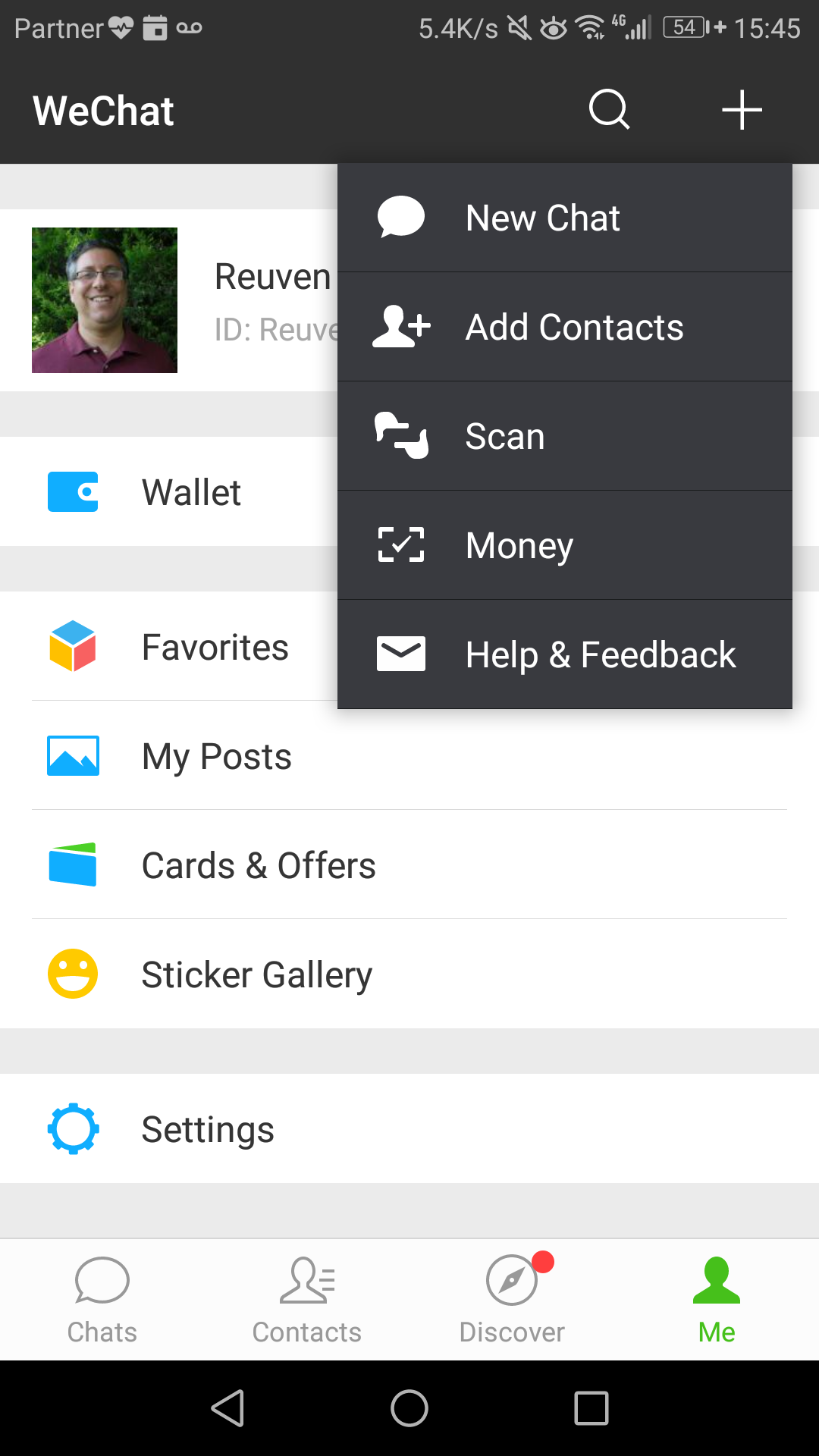
You can then add me by clicking on the “+” at the top of the main menu, and choosing “Scan” from the menu. That’ll start up a scanner for QR codes that uses the phone’s camera.
If you’re new to WeChat, then you’re in for a treat; it’s a great chat program, and there are oodles of groups that you can join. It’s normal for people in China to join lots of groups, and to share their latest photos, experiences, travels, and (of course) meals in “moments.” But we’re going to ignore that functionality here, in order to focus on the payment system.
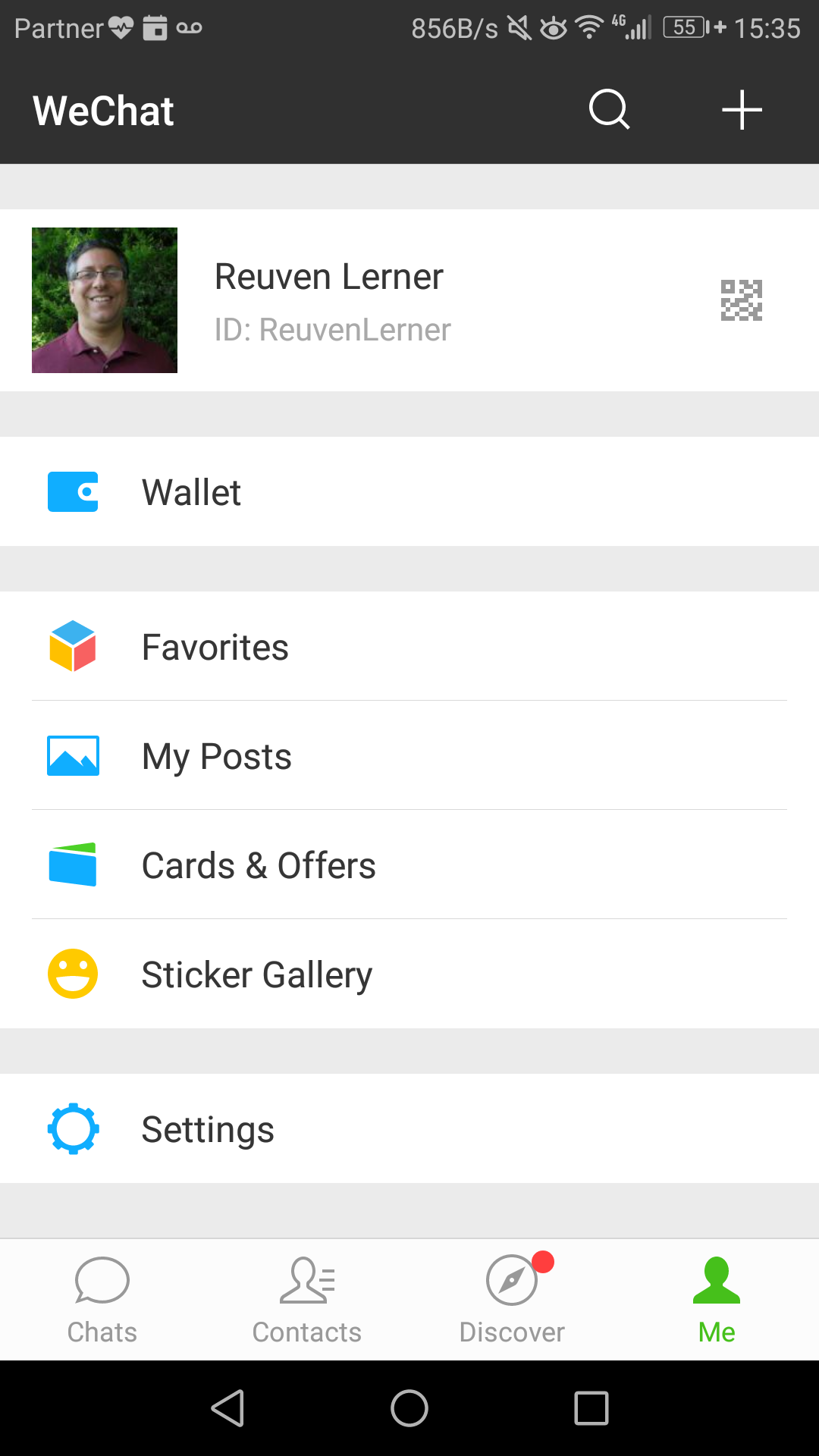
Wallet
In the above screenshot, you’ll see that my “+” menu includes “Money.” Moreover, my personal page (visible in two of the above screenshots) includes the “Wallet” functionality. By default, this will not appear in WeChat. Indeed, when I told Chinese friends that I couldn’t send or receive money, they immediately asked to look at my WeChat home page. They were rather surprised that “Wallet” didn’t appear.
Here’s the thing: The “Wallet” menu item won’t appear until you register with WeChat for payments. But how can you do that? From what I can tell — from personal experience, helping others, and reading online — it’s a multi-step process:
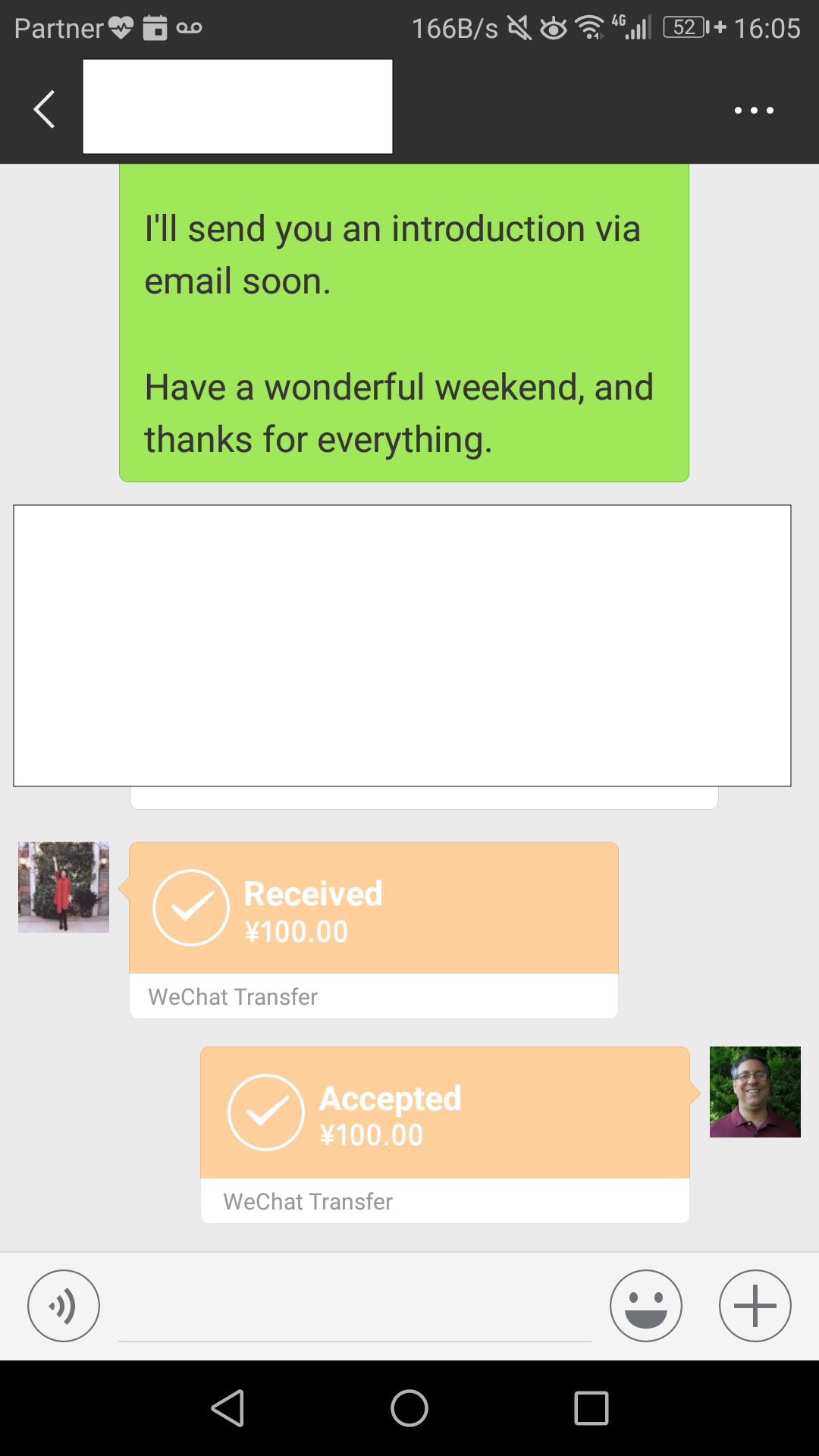
Have someone send you a WeChat payment. That is, ask a friend to send you a payment, even one that is as small as 1 RMB (approx 14 US cents, as of this writing). Now, there are two ways to send someone a payment on WeChat. One is a “payment transfer,” and the other is a “red envelope.” In my experience, things won’t work if the person sends you a red envelope. Rather, have them send a transfer payment. The cost is the same (i.e., free), but until I registered with WeChat for payments, I couldn’t receive red envelopes.
When your friend sends you the transfer payment, you’ll get a special WeChat message saying “Received,” with the amount of money you got.
Note: You still haven’t actually received the money! In order to put it into your account (and no, you don’t have an account yet), you’ll need to accept it. Click on the payment to accept it.
At this point, WeChat will realize that you don’t yet have an account. It’ll prompt you to enter your Chinese bank account number. This is where things can go wrong. Enter your Visa credit-card number. No, it’s not a Chinese bank account number. And yet, it will work. Perhaps other companies’ credit cards will work; I’m really not sure, but it’s worth a shot. You might also need to enter an ID or passport number; once again, this is where I’ve seen things go wrong. In theory, this is where the WeChat folks can and will stop foreigners from using their payment system — but in practice, they’re allowing foreigners to use it.
Once you’ve entered your credit-card info, you’ll be able to accept the payment from your friend. WeChat will show you (as in the above screenshot) that you’ve accepted the payment.
That’s it! You should now have a “Wallet” menu item on your WeChat “me” page. And if you go into your wallet, you should see the payment that your friend sent to you.
You’re now ready to start sending and receiving WeChat payments.
Again: First have someone send you a transfer payment. Then, when you receive the payment, register with WeChat’s accounting system. Use your Visa card instead of a Chinese bank account number, and a passport or ID number instead of the Chinese ID number. If, after doing this, you then see the “Wallet” menu option, you’re (literally) in business!
If this goes wrong — well, there’s no official source of information for what to do; WeChat doesn’t officially support foreigners. And their help system is automated and in Chinese. So here are some suggestions that I’ve seen elsewhere:
Remove and re-install WeChat from your phone. When you remove WeChat, be sure to remove all files and data associated with it.
Change the language from English to Chinese, and back again. If you don’t read Chinese, then note the location of the menus before switching the language.
If it didn’t work for you outside of China, then try to accept the payment within China. For many people, that seems to make the biggest difference.
Security
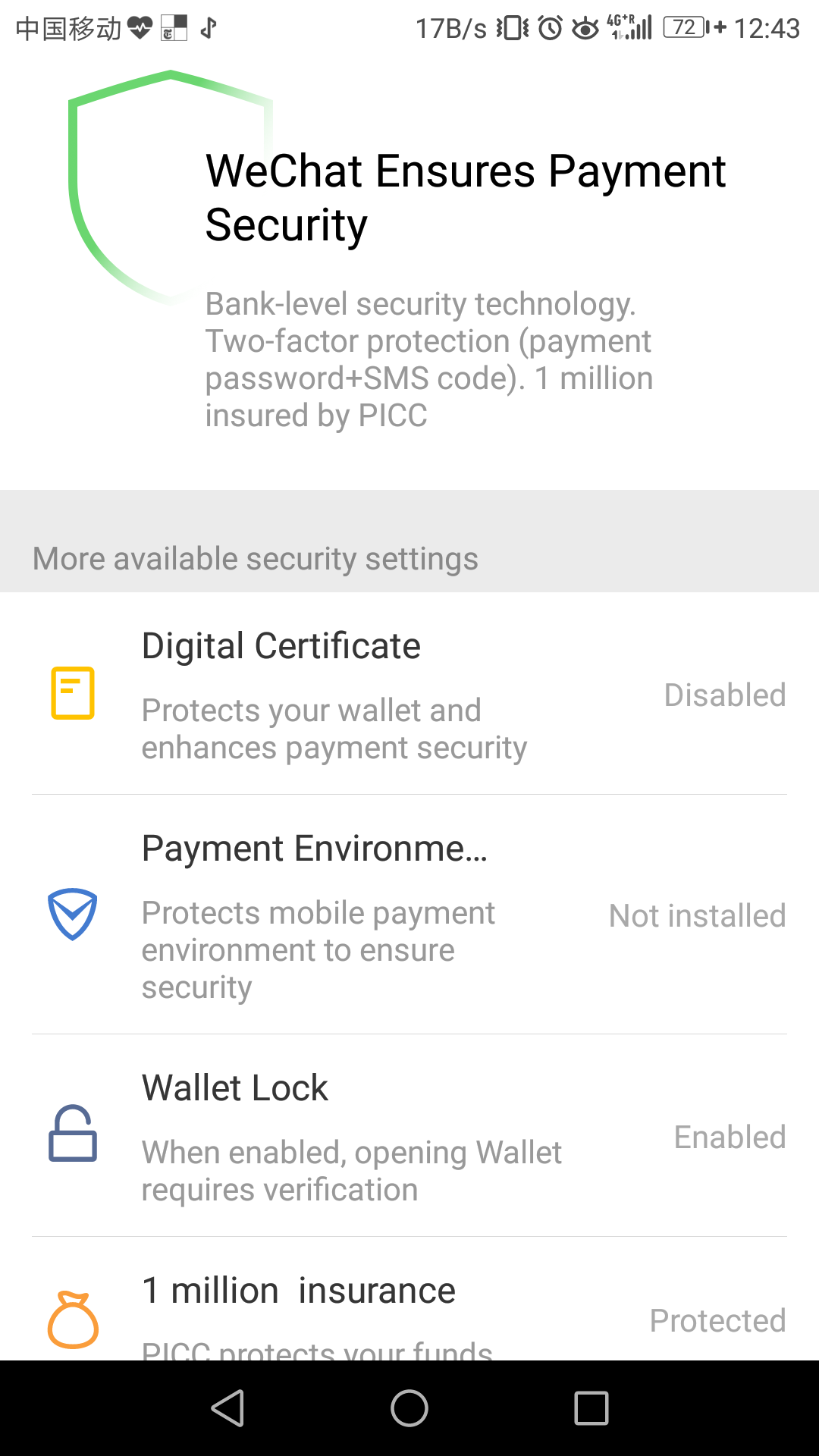
Before you continue, you should add some security to your WeChat wallet. After all, this is a wallet in every way, and can be used for all sorts of payments. If someone steals your phone, then they can use your wallet for payments. (They might disappointed to discover that as a foreigner, you cannot easily add money to your WeChat wallet — but they will be able to spend the money you do have there.)
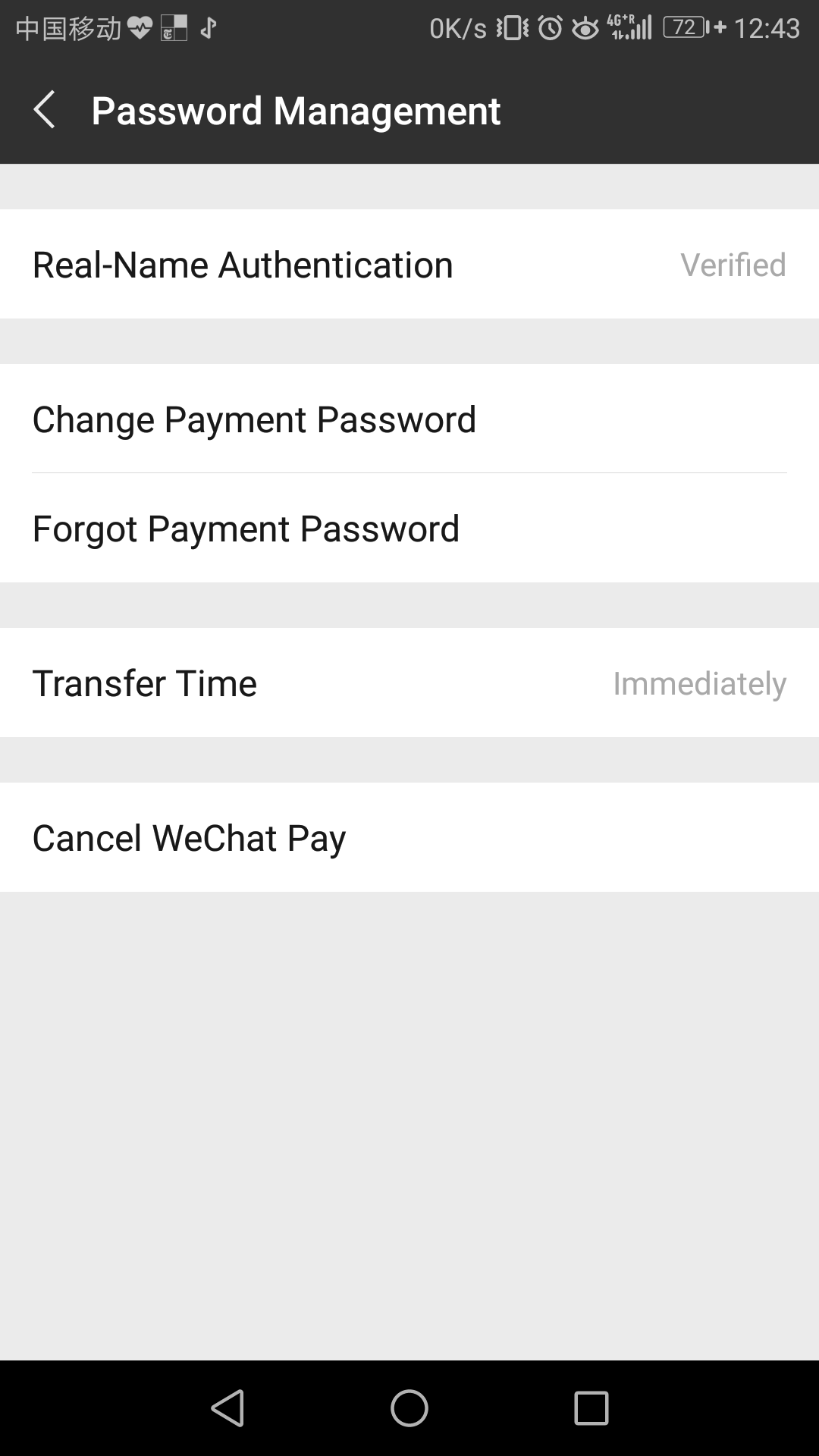
Go to the “Wallet” menu option. In the top right, you’ll see four squares, three empty and one filled in with white. Pressing that takes you to the “Pay Center” screen, with several options, including “payment security” option. You want to turn on “Wallet lock,” which lets you set a pattern password.
In other words: Every time you open your wallet, you’ll need to swipe a pattern of dots in order to use it. That’s a good thing. You can always change the pattern later on, if you want.
You should also set a (separate) password to make payments. This is done via the “manage payments” menu item within the “Pay center” screen, which also calls its “password management.” Every time you make a payment, you’ll need to enter this 6-digit code.
Adding money to your WeChat wallet
If you’re an average Chinese user of WeChat, and you want to add money to your WeChat wallet, then it’s very easy: You “top up” your wallet from your bank account. That’s why you need to enter a bank account into WeChat when you first register.
But if you don’t have a Chinese bank account, then you’re sort of stuck. There are two options that I know of:
Give a Chinese friend cash, and have them send you WeChat money.
This is a popular option among people who are only in China for a short time, or who just want to experiment with WeChat payments. I’ve met a number of foreigners who do things this way. I’m sure that some Chinese are also happy to get foreign currency; I have no idea about the legality of this, and (of course) you need to agree on the exchange rate with whoever is paying you. You can also go to an ATM, withdraw cash, and do the whole process in RMB, which avoids such problems and questions.
My preferred option is to use an online, paid service. I’ve been using VPayfast (http://vpayfast.com/) since I first started to use WeChat payments. The Web site looks like a fly-by-night operation, but I’ve found them to be reliable. They have service (available via WeChat, of course), and while I first used them in English, I then decided to switch to Chinese — and they were far more responsive.
VPayfast moves money between different accounts, and they cover a large number of them. So you can pay with a credit card and get WeChat money. Or you send money to AliPay. Or get money from PayPal. And so forth.
True to their name, I’ve found VPayfast to be very fast; within an hour of entering an order, they charge my credit card and send me a WeChat transfer payment.
My biggest frustration with VPayfast was that they required some documentation before allowing me to use a credit card: I needed to send them a picture of my passport (or ID card), and also show them my credit card (with only the final 4 digits showing). Once I did that, though, it was very fast to add money to my WeChat account.
They do charge for this service, and it’s not small: On a purchase of 1,000 RMB, I paid $173.75, plus a $12.16 service fee. You would think, with such a margin, that they would have money to pay for a nicer Web site! But beggars can’t be choosers, and they have provided me with great service for for many months.
Update: Another service!
After this blog post was published, I discovered another (and different) way to load money onto your WeChat wallet. I haven’t ever used this, so I can’t tell you how good/bad/reliable it is. It’s called “Swapsy,” and the idea is that you say how many RMB you want in WeChat. They find someone who wants the equivalent amount in (for example) USD, via PayPal. They provide each side with the other’s payment details, and let the people exchange money. They claim (of course) that it works well and reliably, and that by checking people’s IDs they’re not going to have problems, and that they guarantee the transaction amount. So it sounds good overall. My biggest problem is that they guarantee transfer of funds within 1 day, which is usually longer than my window of patience or planning allows. But you should know that the service exists.
How to pay
All of this setup is great, but the point of WeChat payments is to pay! So, how does that work? It turns out that there is a wide variety of ways in which to use WeChat payments; it’s more of a platform and ecosystem than a single payment method.
Person to person
The most common, and easiest, method for WeChat payments is person-to-person. The person to whom you’re sending money must already be a WeChat friend of yours. Then, start to compose a message to them. Just as you can add a photo to the message, you can also add a “transfer” to them.
When you press on the “transfer” button, you’ll be asked how much money you want to send to them. Enter an amount in RMB. You’ll then be asked to enter your password. Do that, and — zip! — you’ll see a reddish-orange “transfer” icon appear.
The recipient will see this in their WeChat app, and will then have to accept the transfer. Once they do, you’ll see that they received it (and when). The money will be removed from your account, and placed in theirs. (Actually, the money is typically removed from your account right away, even before they accept the transfer.)
It’s traditional, especially around Chinese New Year, for people to gift “red envelopes” to one another. Obviously, these are traditionally physical envelopes with a red color, with money inside — but WeChat lets you send red envelopes to friends, relatives, and others with great ease. I think that the effect is similar, but I’ve never really sent any red envelopes. I received a few, but that was before I could use WeChat payments, which meant that they expired long ago and are no longer valid.
As a foreigner in China, I’m often using a VPN to access the Internet, either on a WiFi network (e.g., at my clients’ offices, or in my hotel room), or using my phone’s roaming plan. I’ve learned through experience that keeping the VPN on when using WeChat payments means that they’ll take a bit longer, and can sometimes time out. My suggestion is thus to turn off your VPN when you’re using WeChat payments.
You scan them
If you’re transferring money to a friend, then what I described above is the best. But what if you just want to pay someone, such as the owner of a store? In such a case, you can scan them.
Many stores have a WeChat QR code next to the cash register. I’ve similarly seen restaurants where the waitstaff brings you a piece of cardboard with the QR code on it. In any case, the idea behind this code is that you don’t have to be friends with them to pay — you can just scan, enter an amount of money to send them, and authorize the payment.
Taxi drivers all accept WeChat payments using this system: If you ask to pay with WeChat, then they’ll hold up their sign, which you can scan.
You can scan using the “scan” functionality in the main “WeChat” menu. The scanning function will show you the square in which it’s searching for, which makes it easy to aim. Once it finds the QR code, it’ll beep, and then ask you how much you want to pay them. Actually, you normally need to say how much you want to pay; in some cases, it’ll be entered for you automatically.
You then enter your six-digit payment password. After a few moments, you’ll see a “success” page on your phone, and both of you (the person you’re paying and you) will get WeChat messages indicating what you just paid, and to whom.
I have yet to encounter someone who will not take WeChat payments. Fruit vendors on the street, taxi drivers, restaurants, supermarkets — they all take WeChat.
I’m writing this in December 2018, on a trip to Guangzhou and Shanghai. To my surprise, the ticket-vending machines in Shanghai still require that you use cash. (Of course, most locals now use a phone app.) But in Guangzhou, the vending machine lets you press a button to pay with WeChat. When you do that, it pops up a QR code on the screen; you’re expected to scan it within 60 seconds. If you do so, then the vending machine gets a notice indicating successful payment, and gives you a subway-riding token.
I also ordered meals from a delivery service that works with foreigners. (Don’t get me started; both MeiTuan and EleMe, the two main delivery services, don’t know how to deal with foreigners. Grrr.) I ordered on my computer, then said that I want to pay with WeChat. Up popped a QR code, which I scanned on my phone, and approved with my password. Within seconds, the Web site indicated that my payment had gone through, and my order was approved.
They scan you
Some restaurants and stores, and many supermarkets, have a different way of doing things: They scan you, rather than you scanning them. (It’s typical, in such cases, for them to say 我扫你, or “wo sao ni,” meaning, “I scan you.”)
In this case, you need to go into the main “WeChat” menu and choose “Money.” You’ll need to enter your pattern password. This brings up a QR code on a green background that others can scan in order for you to pay them. Don’t share this QR code! People can use it to take money from your WeChat wallet!
The store will have a scanner that they use to look at your phone. You’ll need to approve the payment by entering your password.
Note that once a restaurant has scanned you, it’s quite possible (and common) for them to add you to their WeChat announcement feed. They, of course, are delighted to have additional people following their store and getting announcements (including discount codes). You might be less excited to receive so many announcements; you can always erase them, and stop following the company, afterward.
Integrated with another app
In some cases, programs — especially on the phone — can hook into WeChat for payment. For example, if you want to pay for taxis with Didi, you can do so by specifying WeChat for payment. You’ll need to authorize the connection and payment. It’s pretty straightforward, and simply requires your approval.
Go through a third party
In some cases, for reasons I don’t quite understand, restaurants don’t always run their own payment systems. Rather, they go through MeiTuan or another third-party provider. This is especially true at restaurants that have automated ordering: In those places, you sit down, scan the QR code at your table, choose items from a menu, and pay. The waiter doesn’t need to ask you what you want; he or she just brings it to you when it’s ready. Very convenient, but this is also generally unavailable to foreigners, from what I’ve seen.
In such restaurants, I’ve found that WeChat will time out, have problems, be unable to connect, or even (in some cases) require that you log into a third-party system, such as MeiTuan. This turns out to be a major stumbling block. It doesn’t happen often, but it’s both embarrassing and frustrating when it does.
Fortunately, I’ve found that people in China are very nice and accommodating, especially about these things. (They tend to think that foreigners are weird and don’t understand anything, which lets you get away with quite a lot.) In the cases where it doesn’t work at all, I’ve found that I can generally convince the waiter or cashier to scan me, and do a person-to-person transfer. They can then settle the bill directly with the restaurant.
Things to consider
That’s about it, in terms of the mechanics! Once you get used to using WeChat for payments, everything else will seem primitive and slow in comparison.
But there are things to consider. Here are a few of them.
Transferring from WeChat to a bank account
Forget about it. I’m sure that it’s possible, but you’ll almost certainly end up losing a lot of money in the process. If you’re planning to return to China, just leave the money in the account. And try not to put too much money in your WeChat account at a time.
If you have a bunch of RMB left over at the end of your trip to China, and you don’t want to keep them there — perhaps because you don’t know when you’ll next be returning — then you can ask VPayfast to transfer them back to your credit card. But I have to believe that you’ll lose more than you’ll gain in the process.
A more practical solution is probably to transfer the RMB, via WeChat, to someone else in China. They can then give you cash, or (if they’re a foreigner) even give you your local currency.
AliPay
I’ve ordered from Ali Express for many years. They’re very convenient and inexpensive. They’re also the same parent company (Alibaba) as China’s Taobao and WeChat’s competitor in the phone-payment space, AliPay.
It’s confusing, but phone-based AliPay is not the same as the AliPay you use to order from Ali Express. It took me a long time, and a while talking to various customer-service representatives at AliPay via their online chat system, to figure this out.
Perhaps, at some point in the future, AliPay will allow foreigners to use their system. But for now, stick with WeChat, which seems to work for most of the people, most of the time.
What if they go out of business?
TenCent (the parent company of WeChat) is one of the largest and most profitable Internet companies in the world right now. So yes, it’s possible that they’ll go out of business, taking your WeChat wallet money with you, but it seems unlikely to me. And if they do, hundreds of millions of people in China will freak out — not something that I would want, if I were their business owner.
So yes, you’re basically putting money into a company that’s not a bank, isn’t regulated as one, and which can (in theory) do whatever it wants. And if they decide that you have committed fraud, or some other scam, then good luck arguing with them. I can’t imagine it’ll be easy or straightforward.
My strategy is thus always to have no more than 1,000 RMB in my WeChat wallet. I can add to it whenever I want, and that’s usually good for a few days (at least) when I’m traveling in China. In the worst possible case, that money will be gone, or unavailable for a while. But I wouldn’t put my life savings there, or anything close to it.
What about privacy?
In China? Privacy? Ha!
You have to assume, when you’re in China, that privacy basically doesn’t exist. With WeChat payments, that goes double: Not only should you assume that WeChat has information about what you have bought, and where. You can assume that they have shared your information with all of their customers, and with the government. That’s the way things work in China.
What if I have problems?
From everything I can tell, WeChat’s service is in Chinese only, using a bot. Even if you use the English version of the wallet, all communication with their service will be in Chinese. There is a “help” menu, and it looks like it’s in English… until you enter that part of the app, and then everything is in Chinese.
Bring cash with you, just in case
On a few (rare) occasions, I’ve found that WeChat payments just don’t work. This happened to me much more at the start than has been the case recently; I’m not sure if this has to do with me resetting my phone (as per WeChat’s suggestion) or something else. But I learned to have at least a bit of cash with me, just in case.
Actually, that’s not entirely true: I have had so few problems in the last two trips that I’ve gotten used to going around almost cash free. However, knowing that the Shanghai metro doesn’t take WeChat payments, I made sure to have at least a bit of cash on me, to buy tickets. But I’ve spent five weeks in China over the last six months, and I haven’t been to an ATM even once. Rather, I’ve just used the (little) cash that remained from previous trips.
I hope that this guide helps you! If you have any updates or suggestions, then please let me know — again, I’m “ReuvenLerner” on WeChat, or reuven@lerner.co.il via e-mail and @reuvenlerner on Twitter.
Good news for developers in Israel — I’ll be offering two open-enrollment courses in Tel Aviv next month (January):
Advanced Python: If you’ve already been using Python for at least six months, and want to level up your knowledge of this hot language, then this course is for you. I’ll talk about advanced data structures, inner functions, functional programming techniques, in-depth objects, iterators, generators, decorators, and threading/multiprocessing.
Intro to data science and machine learning: Data science is the hottest topic in the computer world, and Python is the most popular language for doing it! This course will teach you about NumPy, Pandas, and scikit-learn, using a variety of real-world data sets. Learn how to import, select, clean, and analyze data — and then to create and compare machine-learning models that make predictions. Note that this course assumes some familiarity with Python.
These are the same courses I’ve given on-site, around the world, to companies such as Apple, Cisco, Ericsson, IBM, Intel, and VMWare (among many others). The big difference is that now you don’t have to work at a big company to take the course.
Want more information, or to guarantee a spot? Just click on the above links.
Have any questions? Send me e-mail at reuven@lerner.co.il, or call me at +972-54-496-8405.
Are you new to Python, and looking for relatively easy exercises to reinforce what you’ve learned?
Do you use Python every day, but rely on Stack Overflow to answer questions like, “Which parentheses should I use here,” or, “What’s the difference between a list and dict?”
Are you an experienced developer in other languages, and want to learn Python via hands-on practice?
Since I launched it 18 months ago, three cohorts of students have participated in Weekly Python Exercise — receiving a new Python challenge via e-mail every Tuesday, and the solution the following Monday. Students had access to our exclusive forums, and traded ideas, solutions, and techniques with one another. Some attended my live, video office hours, when I answered Python questions that they might have.
The question I got most often about those Weekly Python Exercise cohorts was whether it was appropriate for someone totally new to Python. Many queries later, I decided to launch Weekly Python Exercise, Newbie Edition.
If you want to improve your Python fluency, then there’s no better way than practice. And if you are new to Python, and want to understand the core concepts better, then I’m sure that Weekly Python Exercise is for you.
15 exercises, sent to you each Tuesday — along with a list of subjects covered by the exercise, and links to resources to read on those subjects
When applicable, automated tests (in “pytest”) to help you check your answers
15 detailed explanations, sent to you the following Monday
Exclusive access to a forum in which other WPE students will help one another to solve the problems (and improve on my solutions)
Exclusive access to monthly office hours with me, in which I’ll solve the exercises and answer your Python problems.
And of course, my usual discounts for students, retirees/pensioners, and people from outside the world’s 30 richest countries get significant discounts. (Just contact me to get the appropriate coupon code.)
Today (Monday) is the last day to benefit from my weekend sale, with 40% off of my books and courses! Just enter the coupon code “BF2018” for any product , and take 40% off.
This offer includes my new “Intro Python: Fundamentals” course, containing the 1st day of the 4-day training I give to experienced developers around the world.
Yup — just like everyone else, I’m having a Black Friday sale on all of my online books and courses. Just this weekend, you can use the coupon code BF2018 to improve your Python skills:
Just use the coupon code BF2018 at checkout to get your 40% discount! But hurry, the sale only lasts through “Cyber” Monday. Any questions? Just e-mail me at reuven@lerner.co.il.
You probably want to understand Python better, use it more efficiently, and write code that you (and others) can maintain — for yourself, your current job, and your career.
Weekly Python Exercise lets you make that improvement. Over the course of a year, you learn to solve more interesting, useful, and complex problems. You’ll learn how to use decorators, generators, and comprehensions, as well as inner functions, lambdas, and magic methods.
And you’ll learn not just via your own work, but by collaborating with other Python developers around the world in our private forum. And in monthly office hours with me.
Registration for Weekly Python Exercise is closing soon, and I only open 1-2 cohorts each year. If you want to level up your Python, then WPE is the best way I know of to do so.
Combine the many benefits of WPE for your career with my money-back guarantee, my “forever free” policy gaining you entry into future cohorts, and the discounts I offer to students, retirees/pensioners, and people living in non-wealthy countries, and I hope you’ll agree that Weekly Python Exercise is a great investment.
Not sure? Or are you eligible for a discount code? Or just want to see my e-mail is handled by a bot? In any case, just e-mail me your questions.
Don’t delay. Weekly Python Exercise is starting soon — and along with it, your mastery of Python.
This is just a reminder that registration for the next cohort of Weekly Python Exercise, my course that combines exercises and community to turn you into an advanced Python developer, closes in just two days, on September 18th.
If you’ve always wanted to improve your understanding of such topics as functions, objects, decorators, generators, comprehensions, and lambda (among other things), then WPE is for you! I only open 1-2 cohorts per year, so if you want to level up your Python — and stop relying on Stack Overflow and Google to answer your questions — be sure to check it out.
With this cohort, I’m adding tests with PyTest to most exercise specifications! This means that you’ll not only get better at coding, but at testing, too.
Remember: I offer discounts to students, pensioners, and residents of countries that aren’t among the world’s 30 richest. Just e-mail me at reuven@lerner.co.il for a coupon code.
And: Once you buy WPE, my “forever free” policy means that you can join future cohorts, too.
And of course: There’s a 100% money-back guarantee.
I’m sure that WPE is the best way to improve your Python, and thus improve your career as a developer or data scientist. Questions? Just e-mail me at reuven@lerner.co.il, and I’ll respond ASAP.
Just about every day for the last decade, I’ve taught Python to developers at companies around the world. And if there’s anything that those developers want, it’s to improve their Python fluency.
Being a more fluent Python developer doesn’t only mean being able to solve problems faster and better — although these are nice benefits, for sure!
Being a more fluent Python developers means that you can solve bigger, more complex problems. That’s not only worth something to you, but to your employer, as well.
Developers know this, and are always asking me how they can improve their skills once my courses are over.
My solution is Weekly Python Exercise, a year-long course in which you get to improve your existing Python skills, and learn new ones, as you solve a new exercise each week. Because learning is always more effective with other people, WPE students can use our private forum to discuss solutions, collaborate on the best strategies, and even (much as I hate to admit it) tell me when my solution could have been better.
Oh, and there are live, monthly office hours as well, when you can ask me questions about the exercises. Or Python in general. Or anything, really. It’s your chance to pick my brain, in real time.
If you are tired of searching Stack Overflow every time you start a new Python project, and want to become a more fluent developer, then Weekly Python Exercise is for you.
Note that it’s not a course for beginners! WPE is meant for people who have already learned Python, and are using it, but want to gain fluency. We’ll be dealing with all sorts of advanced topics, too — from inner functions to generators to decorators to object-oriented techniques.